
2026 年3月,加州圣何塞的 GTC 大会上,NVIDIA 明确表示,新一代 Vera Rubin 等旗舰 AI 平台将全面采用液冷,配套 Manifold(歧管)、UQD/MQD(快拆接头)、Cold Plate(冷板)等模块化方案,给全行业传递出一个信号:液冷已经从“可选优化”,变成 AI 工厂时代的必选底座。

在这股浪潮之下,美国在建的是少数超大“AI 算力工厂”,中国则在全国铺开“智算中心网络”。围绕算力中心与液冷方案,中美路线正在拉开清晰的结构性差异。
一、算力投资:美国押“大厂”,中国铺“网络”
美国:云巨头主导的超级 AI 工厂
这轮 AI 基建,核心玩家集中在美国几大云巨头。过去两三年,它们不断上调数据中心与 AI 相关资本开支,用“百亿美元”为单位砸钱。
美国的典型特点是:钱高度集中在少数几家公司手里,集中建设极少数超大体量的算力工厂。
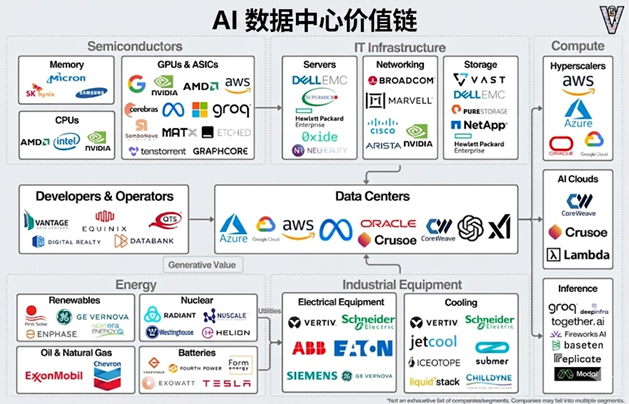
中国:国家工程 + 多主体共建算力底座
中国走的是另一条路。
整体来看,中国更像是在全国铺一张“算力高速网”:单个园区规模不一定最大,但项目数量多、分布广,适配的是“千行百业用 AI”的应用逻辑。
二、园区规模与功率密度:1GW 工厂 vs 100MW 枢纽
美国:接近电厂级别的 AI 园区
美国新一代 AI 数据中心的容量,已经接近传统大型电厂。
在这种规模下,数据中心更像一座“AI 发电厂”,只是输出的是算力而不是电力。
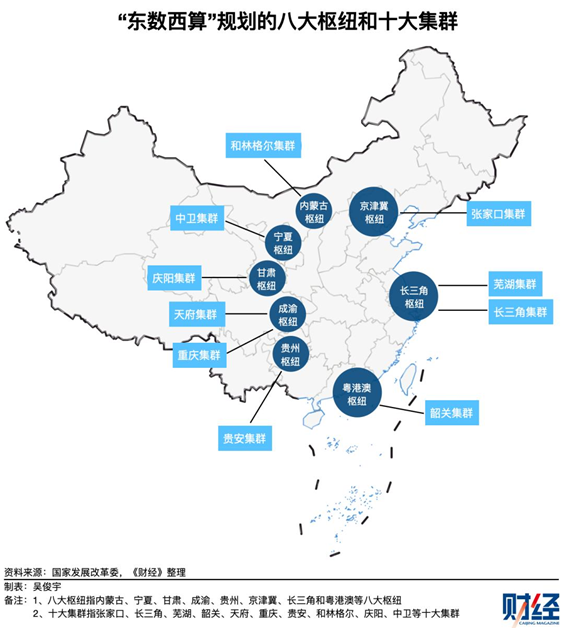
中国:50–150MW 级区域智算中心
中国的做法以“区域智算中心”为主:
可以简化理解为:
三、芯片与整柜方案:NVIDIA 标配 vs 国产多路线
算力中心的核心仍是芯片和整柜平台。
美国:围绕 NVIDIA 的统一生态
在美国,大多数高端训练集群仍围绕 NVIDIA 平台构建:
H100/H200 之后,GB200、B200 等新一代 GPU 加上 NVL72 等整柜方案,成为构建旗舰训练集群的“标配组合”。
这意味着,上游在散热、供电、互联等配套方案上,会以 NVIDIA 的整机柜平台为中心推进标准化。液冷自然也紧跟其后。
中国:国产 GPU 快速爬坡 + 合规使用国际方案
中国则更强调芯片路线的多元化:
这一差异会直接反映到液冷方案、接口标准与整机柜结构上:美国更统一,中国更百花齐放。
四、液冷:NVIDIA 把“底线”抬起来了
液冷是这次 GTC 的绝对主角之一。
1. GTC 2026:旗舰平台“只做液冷”
NVIDIA 在 GTC 2026 上对新一代平台的定位非常直接:
这一步,实际上把整个产业对散热方案的“底线”向前推进了一大截。
2. 模块拆分:Manifold、快拆接头、冷板
与以往只喊“支持液冷”不同,这次 NVIDIA 把液冷拆成几个关键模块:
Manifold(歧管):负责一柜之内冷却液的分配和回收,是整套系统的中枢。
UQD/MQD(快拆连接器):类似“液冷 USB 口”,影响安装维护效率、生态兼容性及漏液风险。
Cold Plate(冷板):直接贴合 GPU/CPU,决定着单芯片热阻和能效上限。
这套拆分方式本质上是在帮产业链“划重点”:
对于中国和美国的液冷供应链来说,这都是非常直接的机会指引。
3. 技术路线:冷板为主,两相/浸没为前沿试验场
从 GTC 相关解读和产业链反馈看:
这套判断,对国内做液冷、材料、结构件的企业都有直接参照意义。
五、中美液冷落地节奏:谁更“激进”?
美国:新建高密度集群几乎天然液冷
在美国,高密度 AI 集群的新建项目基本默认以液冷起步:
总体看,美国在新建高端项目上的液冷采用节奏,明显快于其他地区。
中国:存量风冷 + 新建液冷的加速切换
中国这边则是一个“切换期”:
随着 NVIDIA 等上游平台全面转向液冷,中国新一轮智算中心的默认形态,正在从“风冷为主”加速往“液冷优先”演进。
六、小结:AI 工厂时代,拼的不止是卡,更是“液冷”
站在 2026 年这个时间点回头看,中美 AI 算力中心与液冷路线的大致图景已经比较清晰:
未来几年,谁能在液冷、整机柜方案、算力网络调度和绿色能源上形成更强的综合能力,谁就更有资格在“AI 工厂时代”拿到更多筹码。
